I've been running lots of performance tests on various subsystems lately. I'll have more to write about those in the not-to-distant future but I'd like to share one from this morning.
Thread-safe reference counting is actually quite heavy. I was once told by a former Intel engineer that atomics should be treated as "cacheline nukes".
For those not familiar with reference counting, it's actually rather simple. We can take the quite simplified version below.
typedef struct
{
volatile int ref_count;
} MyStruct;
void ref (MyStruct *s)
{
atomic_inc (&s->ref_count);
}
void unref (MyStruct *s)
{
if (atomic_dec_and_fetch (&s->ref_count) == 0) {
free (s);
}
}
Pretty typical and has a thread-safe mutation of the ref_count, freeing upon reaching zero.
I happen to have a 4th Gen Core Intel processor with TSX extensions to play with. TSX provides the basis for performing hardware assisted transactional memory. I thought I'd cook up a test comparing XBEGIN/XEND to atomic increment/decrement. They work in slightly different ways, for which I thought TSX might be able to perform better in the opportunistic case. Turns out I was wrong. (I love being wrong, I always learn new stuff).
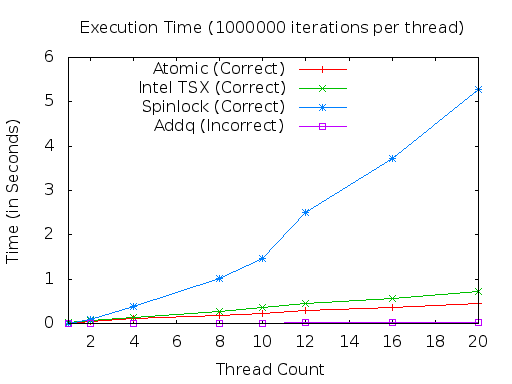
Here is a graph comparing a few different ways. The addq version is not thread-safe.
What we find here is that for thread-safety, atomic is still faster. Bummer.
It is commonly known research in the Garbage Collection community that most objects never live past their first garbage collection (more than 90% in fact).
They actually spend a lot of time designing systems to optimize for this.
(Generational GC for example).
It may be worth optimizing GObject for threaded vs non-threaded cases.
Also iteresting, is that for the non-contended case, spinlocks were faster than transactions. Literature eludes to something otherwise, but I'm just not seeing it.
-- Christian Hergert 2014-04-23